22 Jul 2022
Pythonista is probably the most popular Python app for iOS.
This post is a summary of the work I did to get pip working.
Here’s how to do it:
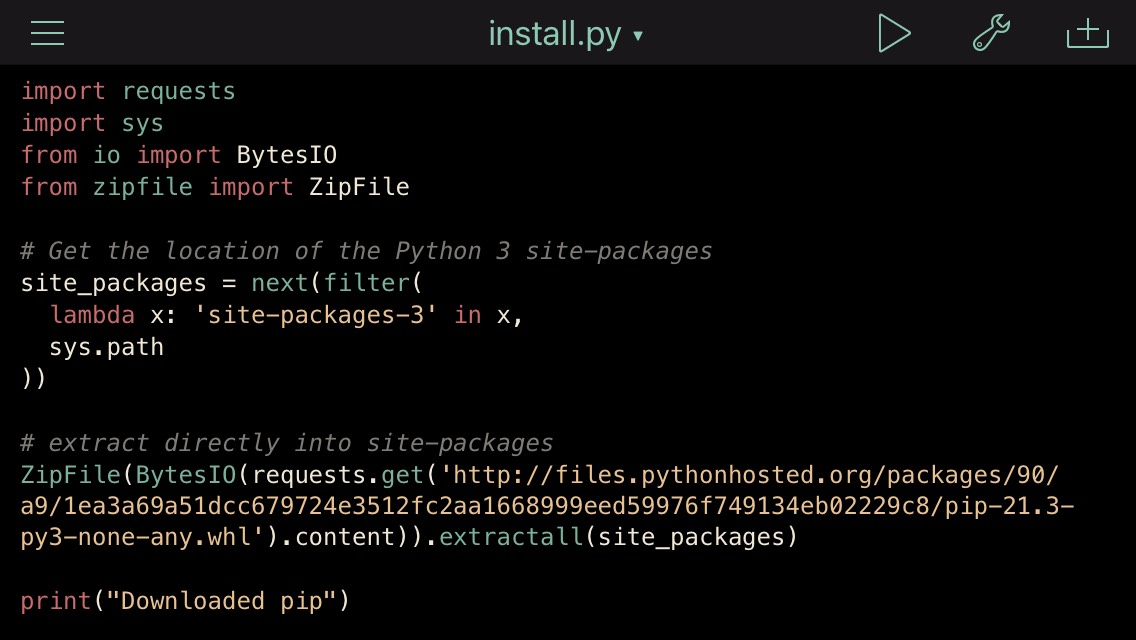
import requests
import sys
from io import BytesIO
from zipfile import ZipFile
# Get the location of the Python 3 site-packages
site_packages = next(filter(
lambda x: 'site-packages-3' in x,
sys.path
))
# extract directly into site-packages
ZipFile(BytesIO(requests.get(
'https://files.pythonhosted.org/packages/90/a9/1ea3a69a51dcc679724e3512fc2aa1668999eed59976f749134eb02229c8/pip-21.3-py3-none-any.whl'
).content)).extractall(site_packages)
print("Downloaded pip")
This downloads pip to the site-packages folder for Python 3.
Pythonista calls this folder site-packages-3.
Now that we have pip set up, we can start downloading our first package:
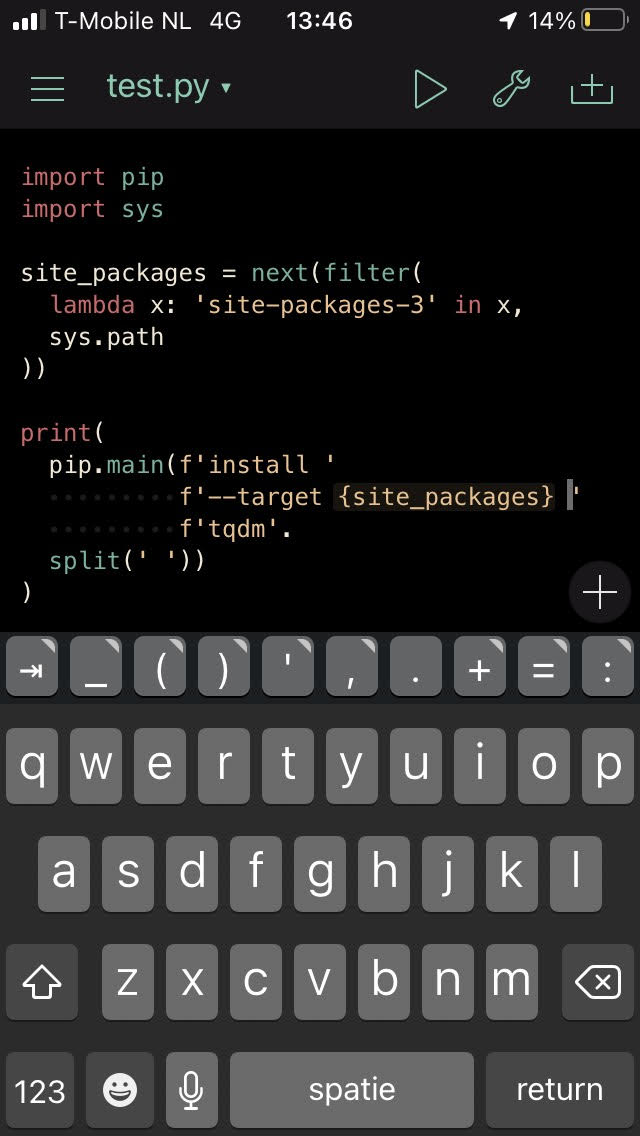
import pip
import sys
site_packages = next(filter(
lambda x: 'site-packages-3' in x,
sys.path
))
print(
pip.main(f'install ',
f'--target {site_packages} '
f'tqdm'.
split(' '))
)
This works a bit differently from how you would typically use pip.
Since we use it as a library, we call the pip.main function with a list of arguments (created by .split(' ')).
The default directory pip tries is not writable.
It’s part of the Pythonista app.
We therefore manually indicate it should write to our site-packages-3 folder using --target.
Note that this probably will not yet work for dependencies with binary extensions (libraries like scipy etc.).
Of course, I also tried to use StaSh.
This seemed quite suitable at first, but upon closer inspection, the pip it contained is not the common version.
In fact it contains its own pip.py which approximates the canonical pip’s behaviour.
In a next post I’ll explore how to use pip to get binary wheels to install on your iDevice.
This will involve building wheels specific for iOS and maybe even setting up a PyPI mirror.
25 Apr 2022
Update 2023-04-21: Everything here describes a hacky solution. The same has now been done properly by the pyodide_http project.
In the previous post I showed how shimming the Python module requests was done.
In the meantime I have made processing binary responses possible, using a slightly weird browser feature that probably still exists for backward compatibility reasons.
Since the requests API is a simple blocking Python call, we can’t use asynchronous fetch calls.
This means XMLHttpRequest is the only (built-in) option to perform our HTTP requests in JavaScript (from Python code).
So the two challenges are that the requests need to be done with XMLHttpRequest, and they should be synchronous calls.
Normally, if you want to do something with the raw bytes of an XMLHttpRequest, you would simply do:
request = new XMLHttpRequest();
request.responseType = "arraybuffer";
// or .responseType = "blob";
However, if this responseType is combined with the async parameter set to false in the open call, you get the following error (and deprecations):
request = new XMLHttpRequest();
request.responseType = 'arraybuffer';
request.open("GET", "https://httpbin.org/get", false);
request.send();
// Synchronous XMLHttpRequest on the main thread is deprecated because of its detrimental effects to the end
// user’s experience. For more help http://xhr.spec.whatwg.org/
// Use of XMLHttpRequest’s responseType attribute is no longer supported in the synchronous mode in window context.
// Uncaught DOMException: XMLHttpRequest.open: synchronous XMLHttpRequests do not support timeout and responseType
The Mozilla docs provide helpful tricks for handling binary responses, back from when the responseTypes arraybuffer and blob simply didn’t exist yet.
The trick is to override the MIME type, say that it is text, but that the character set is something user-defined: text/plain; charset=x-user-defined.
request.overrideMimeType("text/plain; charset=x-user-defined");
request.responseIsBinary = true; // as a custom flag for the code that needs to process this
The request.response we get contains two-byte “characters”, some of which are within Unicode’s Private Use Area. We will need to strip every other byte to get the original bytes back.
Note that the following code block contains Python code made for Pyodide. The request object is still an XMLHttpRequest, but it’s accessed from the Python code:
def __init__(self, request):
if request.responseIsBinary:
# bring everything outside the range of a single byte within this range
self.raw = BytesIO(bytes(ord(byte) & 0xff for byte in request.response))
Even though this works right now, some concessions have been made to achieve the goal of performing HTTP requests from Pyodide.
The worst concession is running on the main thread, with the potential of freezing browser windows.
The future of this project is to write asynchronous Python code using aiohttp, and shim aiohttp to use the Javascript fetch API.
To see all these things in action, check the current state of shimming requests on Github: bartbroere/requests#1
Update 2023-04-20: I’m no longer maintaining and hosting a custom Pyodide build to demonstrate it. The link to it has been removed.
05 Nov 2021
Update 2023-04-21: Everything here describes a hacky solution. The same has now been done properly by the pyodide_http project.
The Pyodide project compiles the CPython interpreter and a collection
of popular libraries to the browser. This is done using emscripten and results
in Javascript and WebAssembly packages.
This means you get an almost complete Python distribution, that can run completely in the browser.
Pure Python packages are also pip-installable in Pyodide, but these packages might not be usable if they (indirectly)
depend on one of the unsupported Python standard libraries.
This has the result that you can’t do a lot of network-related things. Anything that
depends on importing socket or the http library will not work. Because of this, you can’t use the popular library
requests yet.
The project’s roadmap has
plans for adding this networking support,
but this might not be ready soon.
Therefore I created an alternative requests module specifically for Pyodide, which bridges the requests API and makes
JavaScript XMLHttpRequests. I’m currently developing it in a fork at
bartbroere/requests#1.
Helping hands are always welcome!
Since most browsers have strong opinions on what a request should look like in terms of included headers and cookies,
this new version of requests will not always do what the normal requests does. This can be a feature instead of a bug.
For example, if the browser already has an authenticated session to an API, you could automatically send authenticated requests
from your Python code.
This is the end result, combined with some slightly dirty hacks (in python3.9.js) to make the script MIME type text/x-python evaluate automatically:
<script src="https://pypi.bartbroe.re/python3.9.js"></script>
<script type="text/x-python">
from pprint import pprint
import requests
pprint(requests.get('https://httpbin.org/get', params={'key': 'value'}).json())
pprint(requests.get('https://httpbin.org/post', data={'key': 'value'}).json())
</script>
Hopefully, my requests module will not have a long life, because the Pyodide project has plans to make a more sustainable solution.
Until then, it might be a cool hack to support the up to 34K libraries that depend on requests
in the Pyodide interpreter.
19 Mar 2021
In Python 2 Django prefers using the __unicode__ member of any class to get human-readable strings to its interfaces. In Python 3 however, it defaults to the __str__ member. Porting guides and utilities specific to Django used to solve this by suggesting having a __str__ method, with the python_2_unicode_compatible decorator on the class.
This was a nice enough solution for a long time, for code bases migrating from Python 2 to Python 3 or wanting to support both at the same time.
However, with the official deprecation of Python 2 on January 1st 2020, adding this decorator started making less sense to me.
Now you definitely only should support Python 3 runtimes for Django projects.
As an additional porting utility, I created a fixer for 2to3, that renames all __unicode__ dundermethods to __str__, where possible.
The current status of the fixer util is that I have created a pull request on the 2to3 library (even though I’m not sure whether it will be accepted).
Update: lib2to3 is no longer maintained, so just get the fixer from the diff of the closed pull request if you want to use it.
21 Dec 2020
A year after Python 2 was officially deprecated, 2to3 is still my favourite tool for porting Python 2 code to Python 3.
Only recently, when using it on a legacy code base, I found one of the edge cases 2to3 will not fix for you.
Consider this function in Python, left completely untouched by running 2to3.
It worked fine in Python 2, but throws RecursionError in Python 3.
(It is of questionable quality; I didn’t make it originally).
def safe_escape(value):
if isinstance(value, dict):
value = OrderedDict([
(safe_escape(k), safe_escape(v)) for k, v in value.items()
])
elif hasattr(value, '__iter__'):
value = [safe_escape(v) for v in value]
elif isinstance(value, str):
value = value.replace('<', '%3C')
value = value.replace('>', '%3E')
value = value.replace('"', '%22')
value = value.replace("'", '%27')
return value
But why? It turns out strings in Python 2 don’t have the __iter__ method, but they do in Python 3.
What happens in Python 3 is that the hasattr(value, '__iter__') condition becomes true, when value is a string.
It now iterates over each character in every string in the list comprehension, and calls itself (the recursion part).
But… each of those strings (characters) also has the __iter__ attribute, quickly reaching the max recursion depth set by your Python interpreter.
In this function it was easy to fix of course:
- Either the order of the two
elifs can be swapped
- or we exclude strings from the iter-check (
elif hasattr(value, '__iter__') and not isinstance(value, str))
The more labour-intensive way of fixing it would be rewriting it entirely, since the only thing it actually really does is recursively URL encoding (but for four characters only).
Maybe there’s a (bad) reason it only URL encodes these four characters, so that was a can of worms I didn’t want to open.
Anyway, main lesson for me was: even though Python 2 is gone, you might still need to remember its quirks.
